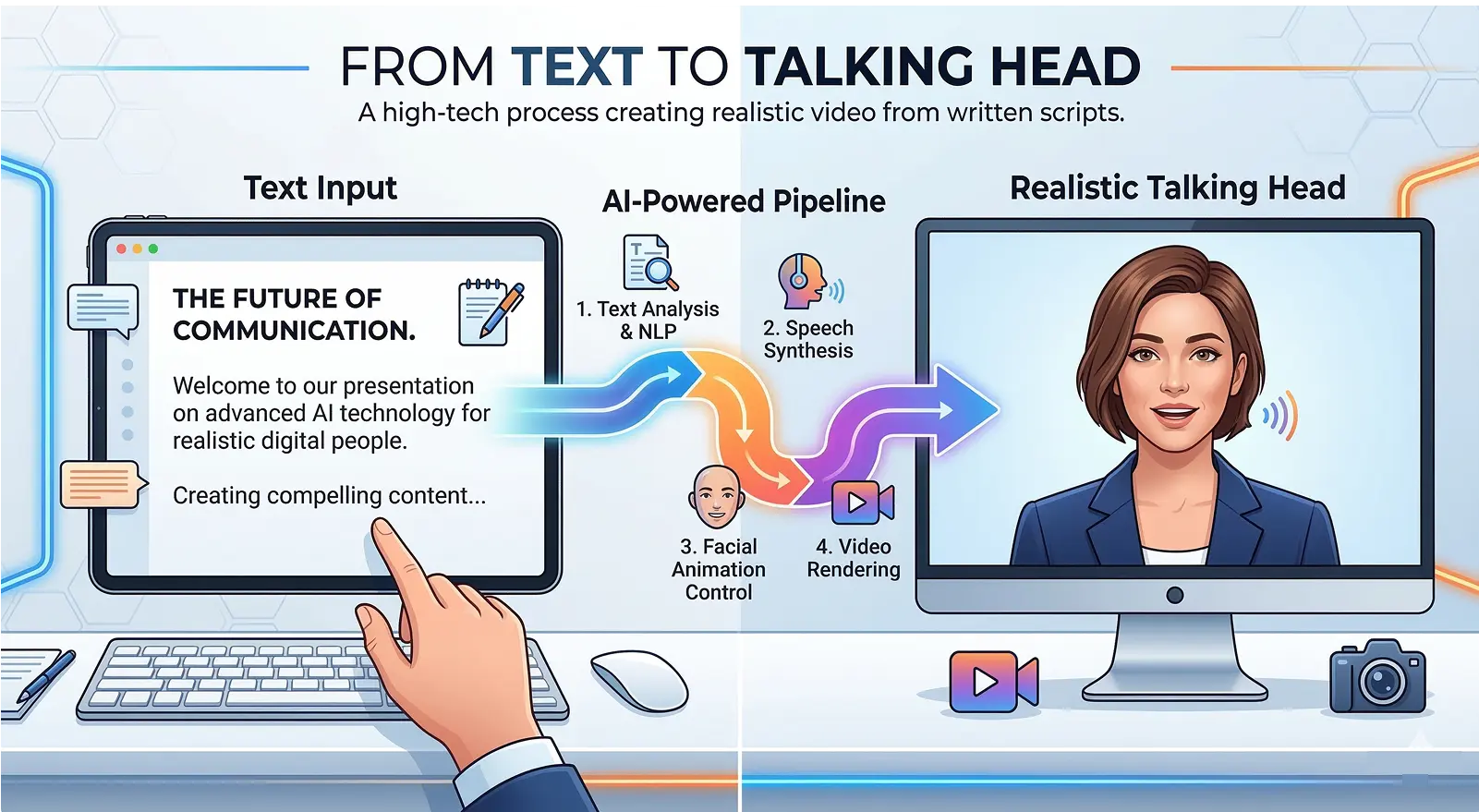
"From Text to Talking Head" is essentially a high-tech pipeline that turns a written script into a realistic video of a person speaking.
Think of it as the ultimate evolution of "text-to-speech"—instead of just hearing a voice, you see a human face with matching lip movements, expressions, and gestures.
Here is the breakdown of how this tech works and why it’s changing the game.
How It Works: The Three Pillars
How do we create an effective and consistent 'Talking Head'? By mastering:
- Voice generation (text-to-speech): The AI produces complete-sounding text using modern technology (such as neural networks) so that it doesn't sound robotic.
- Lip-Syncing (phoneme mapping): The AI measures how to move a mouth in reaction to each phoneme sounded in the audio track using a method like Wav2Lip to ensure the 'visual mouth' and 'audio sound' match perfectly.
- Animation and Rendering: This is the 'magic' part of the process. The AI creates very realistic facial micro-expressions (eyebrows go up, heads tilt) so that the character looks like they have life and not just like a mannequin.
| ID | Process Stage | Human-to-AI Translation Workflow |
|---|---|---|
| TH-01 | Script Parsing | Analyzing text for emotional cues and
punctuation-based pauses to prepare the AI for rhythmic speech delivery. Natural Language Sync |
| TH-02 | Vocal Synthesis | Converting text into high-fidelity audio (TTS) or processing uploaded audio to extract pitch and tone data. |
| TH-03 | Lip-Sync Alignment | The 3D Forge matches vocal frequencies to specific lip
shapes (visemes) for ultra-realistic mouth movements. Viseme Mapping |
| TH-04 | Micro-Expression Layering | Injecting non-verbal behaviors like blinking,
swallowing, and nostril flare based on the intensity of the audio. Biometric Simulation |
| TH-05 | Volumetric Output | The final fusion of audio and 3D mesh, rendered into a video format that preserves depth and head rotation. |
Reasons for Its Popularity
Ultimately, this technology will allow for significantly upgraded scalability of your video by eliminating the expenses associated with traditional filmmaking.
- No More Reshoots: If a typo is discovered in the script, just make the correction(s) and regenerate the video. There is no longer a requirement to have the actor return to the studio.
- Instantly Translate: You can write a script in English and instantly have the "Talking Head" read out the video in fluent Spanish, Mandarin, or French, while maintaining proper lip synchronization.
- 24/7 Content Production: You can create "AI News Anchors," or automated customer service representatives, that may produce content continually as news breaks.
Challenges to Reality Check
Though the technology can be extremely impressive, it may not always yield a quality result:
- Uncanny Valley: At times the eyes can have a slightly "glassy" appearance or the movements of the head may look robotic, possibly leaving viewers feeling uncomfortable.
- Lack of Emotional Transfer: While AI's ability to show emotion in its performance still remains poor. While it can perform "business professional" very well, it struggles with "bawling with grief" or "overwhelmed with laughter," which may lead to an awkward performance.
- Ethics: The majority of systems we see today are built on the foundations that are used to produce DeepFake videos. Many companies utilizing this technology (for example, HeyGen and Synthesia) have very strict policies that require the user's permission to prevent any unauthorized video/images using someone’s likeness.
Submit Your Application
Complete the form below to initiate your AI video generation project.
1. "Ear to Mouth" Synchronization
The biggest challenge of this technology is not so much the picture but rather the timing involved.
- Audio Analysis: AI is able to hear and understand speech by breaking down words into phonemes (smallest sound units).
- Viseme Mapping: There is a corresponding mouth shape (viseme) for every sound produced. Viseme mapping is done by AI in real time. When AI misaligns the viseme by even a fraction of a second, the human brain perceives the video to not be realistic.
2. "Neural Rendering" – More than Just the Mouth
A head that speaks does not merely involve motion of the mouth. Speaking while maintaining a fixed gaze will make you appear like a statue. Neural rendering is capable of producing realistic representation of:
- Micro-Movements: Random eye blinks, slight flaring of nostrils, and crinkles in forehead as we place emphasis on a particular word occur as a result of neural rendering.
- Head Position Estimation: Head will tilt downward when you convey something heavy and upward when questioning. These movements will occur naturally from usage of neural rendering in conjunction with audio cues.
3. One-Shot vs. Fine-Tuning Approaches
The method by which the creates the facial representation of the user(s) consists of two basic methods:
- One Shot Learning: You provide the AI with one image of yourself. The AI will perform a "warp" of that image to cause it to mimic talking. One shot learning will produce an audio/visual representation of you quickly and cheaply; however, if the head turns, the side of the face may appear as being 'smudged'.
- Professional Fine Tuning: Record approximately 2-5 minutes of video of a person speaking. The AI will analyze the face from all angles to create a Digital Double of that person that is virtually indistinguishable from the actual subject.
Workflow for the Content Creator
If you plan to use this tool for a blog or company, the workflow would consist of:
- Upload your script to the tool.
- Select a voice persona (ie: 'professional male' or 'energetic female') type.
- Select from pre-existing stock avatar to be the 'actor' (or upload your own photo).
- Choose from available environments (office, studio, green screen).
- The cloud server will then take all four layers and combine them into an MP4 file.